4.2 Measures of Central Tendency: Mean, Median, and Mode
While charts are frequently very useful to visually represent data, they are inconvenient for the simple reason that they are difficult to display and can not be remembered "by heart". It is frequently useful to reduce data to a couple of numbers that are easy to remember, easy to communicate, yet capture the essence of the data they represent. The mean, median, and mode are our first examples of such computed representations of data, and we will discuss how to use Excel to compute each of them.
The Mean
The mean represents the average of all observations. It describes the "quintessential" number of your data by averaging all numbers collected. The formula for computing the mean is easy:
mean = (sum of all measurements) / (number of measurements)
In statistics, two separate letters are used for the mean:
- the Greek letter
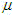 (mu)
is used to denote the mean of the entire population, or population mean
(mu)
is used to denote the mean of the entire population, or population mean - the symbol
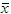 (read
as "x bar") is used to denote the mean of a sample, or sample
mean
(read
as "x bar") is used to denote the mean of a sample, or sample
mean
Another way to show how the mean is computed is:
where n stands for the number of measurements, x stands for the individual
measurements, and the Greek symbol sigma stands for "sum of". That formula is
valid for computing either the population mean
![]() or
the sample mean
or
the sample mean ![]() .
.
Of course, the idea -
ultimately - is to use the sample mean
![]() as
an estimate for the population mean
as
an estimate for the population mean
![]() (which
is usually not known). For now, we will just show examples of computing a
mean, and later we will discuss in detail how exactly the sample mean can be
used to estimate the population mean.
(which
is usually not known). For now, we will just show examples of computing a
mean, and later we will discuss in detail how exactly the sample mean can be
used to estimate the population mean.
Example: A sample of 7 scores from people taking an achievement test were taken. The numbers are:
95, 86, 78, 90, 62, 73, 89
Then the mean of that sample is:
Excel actually provides a simple function for computing averages, namely the
=average(RANGE)
function. Using Excel, we can simply compute the above mean by entering the seven data observations into a new spreadsheet, then find a convenient spot to display the average number, and finally entering the appropriate =average(RANGE) function, where RANGE should be replaced by the appropriate range of cells. Try it out now - the answer should of course be 81.9
Note: In Excel the =average(RANGE) function ignores cells containing no data, i.e. cells that contain no data do not contribute anything to the computation of the mean. Cells that contain a zero do, however, contribute to the average.
The mean applies to numerical variables, and in some situations to ordinal variables. It does not apply to nominal variables.
The Median (or Middle Number)
The median is that number from a population or sample chosen so that half of all numbers are larger and half of the numbers are smaller then that number. The computation is actually different for an even or odd number of observations.
IMPORTANT: Before you try to determine the median you must first sort your data in ascending order.
Example: Compute the median of the numbers 1, 2, 3, 4, and 5.
The numbers are already sorted, so that it is easy to see that the median is 3 (two numbers are less than 3 and two are bigger).
Example: Compute the median of the numbers 1, 2, 3, 4, 5, and 6.
The numbers are again sorted, but neither 3 nor 4 (nor any other one of these numbers) can be the median. In fact, the median should be somewhere between 3 and 4. In that case (when there are an even number of numbers) the median is computed by taking the "middle between the two middle numbers". In our case the median, therefore, would be 3.5 since that is the middle between 3 and 4, computed as (3 + 4) / 2.
Note that indeed three numbers are less than 3.5, and three are bigger, as the definition of the median requires.
For larger data sets, the median can be selected as follows:
- Sort all observations in ascending order
- If n is odd, pick the number in the (n+1)/2 position of your data
- If n is even, pick the numbers at positions n/2 and n/2 + 1 and find the middle of those two numbers
Note that this does not mean that the median is (n+1)/2 (if n is odd) but rather that the median is that number which can be found at position (n+1)/n.
The median is usually easy to compute when the data is sorted and there are not too many numbers. For unsorted numbers, or for lots of numbers, the median becomes quite tedious, mainly because you have to sort the data first. But of course Excel has a built-in function
that will automatically compute the median of the numbers in a given range of cells.=median(RANGE)
Note: In Excel the =median(RANGE) function ignores cells containing no data, i.e. cells that contain no data do not contribute anything to the computation of the median. Also, for an even number of numbers the median is automatically computed to be the middle between the two middle numbers.
The median applies to numerical variables, and in some situations to ordinal variables. It does not apply to nominal variables.
Discussion Topic: Discuss how to find the mean and the median of ordinal data, and why neither of these descriptive parameters makes any sense for nominal variables.
The Mode
The mode is that observation that occurs most often. It is usually not unique, and is therefore not that often used, but it has the advantage that it applies to numerical as well as categorical variables. As with the median, the mode is easy to find if the data is small and sorted:
Example: Scores from a test were: 1, 2, 2, 4, 7, 7, 7, 8, 9. What is the mode?
The mode is 7, because that number occurs more often than any other number.
Example: Scores from a test were: 1, 2, 2, 2, 3, 7, 7, 7, 8, 9. What is the mode?
This time the mode is 2 and 7, because both numbers occur three times, more than the other numbers. Sometimes variables that are distributed this way are called bimodal variables.
For data that consists of lots of numbers, and/or data that is not sorted, the mode, as the median, is cumbersome to compute by hand. Of course Excel provides an appropriate formula, in this case the
=mode(RANGE)
function. However, if the cell range consists several numbers with the same frequency (i.e. a bimodal variable as in the second example above) then the Excel =mode(RANGE) function returns only the first (smallest) number as the mode.
If all values occur exactly once, the Excel mode function returns N\A for "not applicable".
Mean, Median, and Mode: Pros and Cons
Since there are three measures of central tendency (mean, median, and mode), it is natural to ask which of them is most useful (and as usual the answer will be ... "it depends" -:)
The usefulness of the mode is in the fact that it applies to any variable. For example, if your experiment contains nominal variables then the mode is the only meaningful measure of central tendency (you could of course use frequency histograms to represent your data, as discussed in the previous chapter).
Mean and median usually apply in the same situations, so it is more difficult to determine which one is more useful. To understand the difference between median and mean, consider the following example:
Example: Suppose we want to know the average income of parents of students in this class. To simplify the calculations and to obtain the answer quickly, we randomly select 3 students as a sample at random. Let us consider two possible scenarios:
- Case 1: The three incomes may be, say, 25,000, 30,000, 35,000
- Case 2: The three incomes may be, say, 25,000, 30,000, 1,000,000
Compute mean and median in each case and discuss which one is more appropriate.
The actual computations are pretty simple.
- In case 1 the mean is 30,000 and the median is also 30,000.
- In case 2 the mean is 351,666, whereas the median is still 30,000
Clearly we were unlucky in case 2: one set of parents in this sample is very wealthy, but that is - probably - not representative for the students of the class. However, we selected a random sample, so scenario 1 is equally likely as scenario 2. Therefore it seems that the median is actually a better measure of central tendency than the mean, especially for small numbers of observations. In other words:
- the mean is influenced by extreme values, more so than the median
- the median is more stable and is the better measure of central tendency
However, for large sample sizes the mean and the median tend to be close to each other anyway, and the mean does have two other advantages:
- the mean is easier to compute than the median since it does not require sorted observations
- the mean has nice theoretical properties that make it more useful than the median
We will use both mean and median in the remainder of this course, while the mode will be less useful for us and will usually be ignored.