{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
-COOH
Generally, are carbohydrates more or less water soluble than fatty acids? Why?
Please note this first: Most of the illustrations needed to help in constructing your molecules are indicated here as links instead of including all of the illustrations themselves. Click on each link to see the illustrations. You may print the illustrations (each separate link) if you wish, though you will have to adjust the size of some for printing. However, for use during the lab session it is expected that you will bring your laptop to the lab where you will have access to the SHU network and the internet through your wireless connection.
Your lab instructor will help you with getting the "Molecules 3D-Pro" program started if you have trouble. You will use this program to manipulate molecular models. You should open that application first and activate the "trackball" as follows.
1. During computer startup you should see a window called "Novell-delivered
Applications." In that window double click the "Molecules 3D-Pro"
icon. A layout page will appear.
2. Click the trackball icon on the toolbar (10th button from the
left; green ring with white center).
3. When the trackball window appears, click "Preferences" and then
"Full feature" and "OK." Then, you're ready to get a molecule.
4. On the file menu, click "Import Molecule."
5. In the "folders" window of the box that appears you'll see an
open "m:\" folder. Under that is a "moleculs" folder; double
click it to open if it isn't already open. Therein are several more
folders.
6. Double click one of the closed folders ("aminoac" e.g.), and
you'll see the "file name" box fill up with names of molecules, all with
".m3d" endings. Double click one of those to display the molecule:
"alanine.m3d" for example. Alanine is an amino acid
7. Three of the toolbar buttons will show you:
* a wireframe structure (7th button from the
right),
* a ball-and-stick structure (6th button from
the right),
* a space-filling structure (5th button from
the right).
8. The toolbar's 4th button from the right (looks like a tilted
figure 8) will animate the model. Click button to start, again to stop.
9. To control the model (size and movement) yourself, use the trackball
(below).
10. When done with that molecule, single left click on the model
and press "delete." Then "import" another molecule (file menu).
TRACKBALL usage: (You must have a molecule displayed in order for
the trackball controls to respond.)
a. Click the "translate/scale" radio button.
(1) To move molecule: Left click/hold down left
mouse button on trackball's black center; then move mouse.
(2) To change molecule's size: Left click/hold
down left mouse button on trackball's green band; then move mouse.
b. Click the "rotate" radio button.
(1) To rotate molecule in one plane: Left click/hold
down left mouse button on trackball's green band; then move mouse.
(2) To rotate molecule in all planes: Left click/hold
down left mouse button on trackball's black center; then move mouse.
In the following instructions, you'll find the paths to the molecules
to be studied shown in brackets [ ]. Example, to see methane:
File menu, then Import Molecule,
then moleculs folder, then hydrcarb folder, then methane.m3d.
You can minimize and restore this window as needed during your work, as you switch between the on-line guidesheet in its window and the "Molecules 3D-Pro" window. That will save time.
TO CLOSE the "Molecules 3D-Pro" program...click the X button at top right, like any other Windows application.
You may already know that the molecule called insulin is required for regulation of glucose concentration in the human blood stream. Without insulin, death is inevitable. The molecule called collagen is required for formation of connective tissues in the human body. The production of defective collagen during embryonic development would lead to terrible distortions of body structure, even death. The molecule known as reverse transcriptase is required for the AIDS virus to reproduce and to cripple the immune system. All three of these molecules, which have such different functions, are proteins, three members of the same group of biologically important organic molecules.
How is it possible for members of the same molecular group to have such radically different functions within the same organism. Examination of the 3-dimensional structures of these three shows that they are quite different. The relationship between structure and function is a theme that runs through this course and through all of biology, at all levels of organization.
Insulin, collagen, and reverse transcriptase differ in size, molecular weight, and shape. Close inspection would reveal that all three are made from the same group of only five chemical elements: C, H, N, O , S. In fact, there are thousands of types of proteins, all of them made from this same set of only five elements. Different numbers, proportions, and arrangements of these five elements could produce a huge number of possible proteins. We understand how poisons have their lethal effects, how antibiotics cure infections, how a simple amino acid temporarily relieves the terrible symptoms of Parkinson's disease, for example, because research revealed the stuctures of the molecules and showed the way to understanding how the molecules act in living systems.
Although molecules in a given organic group (monosaccharides, for example) share some properties, each individual type of molecule in the group has a unique set of properties: shape, size, charge, and others. Nearly everything that happens in a living cell (and, therefore, in the bodies of plants and animals) involves molecules "recognizing" other molecules. In digestion of food, transmission of messages in the nervous system, muscle contraction, taste, sexual development, and so on, the proper combinations of molecules must recognize each other in order for such processes to occur. How does molecular "recognition" take place? Try to picture this in terms of complementary shapes, like two interlocking pieces of a jigsaw puzzle. Two jigsaw pieces that are not complementary will not fit together, will not "recognize" each other; likewise, in the case of molecules. The study of molecular models should be as much a part of your foundation as studying cells and tissues with a microscope and doing anatomical dissections.
There are several ways of representing molecules on a printed page,as you've seen in your textbook. Some are better than others. Different drawings reveal different features of molecules. Unfortunately, all drawings are "trapped" on the flat page, and that can cramp one's thinking about the molecules in two ways. First, it is difficult to imagine what a molecule might look like from a different angle than the one shown. Second, free bond rotation allows most molecules to take on many different shapes, though one is usually favored over others. A drawing on a page does not allow us to examine variation in structure. The lectures stress this concept.
As you now begin to build representative models, using a model kit, think carefully about the many structural features of molecules that have been covered in lecture and in the text study assignment for today's work. Since some of the ideas you have heard or read so far may not yet be clear to you, this exercise is designed to help.
In the illustrations that you will see, the "ball-and-stick" type of model is like the ones you will build. The "space-filling" models more nearly reflect the actual space that each molecule occupies. Although the models don't show the electrons around the atomic nuclei, those electrons do occupy space; the space-filling models reflect that feature.
Your kit should contain the following pieces.
28 black carbon atoms
20 red oxygen atoms
6 blue nitrogen atoms
60 white hydrogen atoms
100 green cylinders, to represent single covalent bonds between atoms
8 flexible pieces of tubing, used in
pairs, to represent double covalent bonds
When you have finished today's work, dismantle the models COMPLETELY before putting the pieces back into the bag.
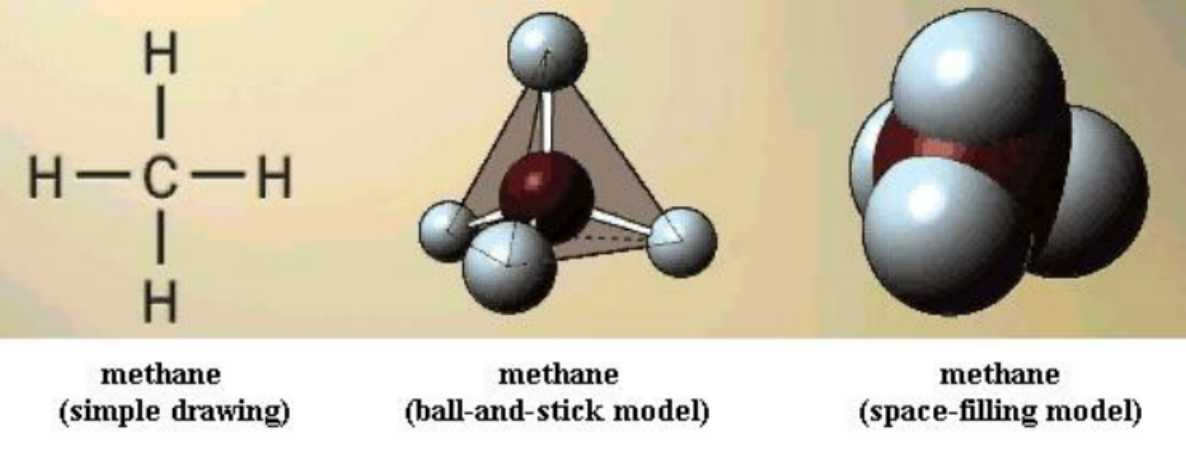
Tetrahedral symmetry and free bond rotation
Since carbon's four bonds are usually arranged in space in tetrahedral form, it is important to have a clear picture of that. This simple fact affects molecular structure as you will soon see. Build a model of CH4, methane [File menu, then Import Molecule, then moleculs folder, then hydrcarb folder, then methane.m3d] Its structure looks the same no matter how you turn the model. All of the C-H bonds are single bonds. Note that you can "spin" a H nucleus at the end of its bond without breaking the bond; this is free bond rotation.
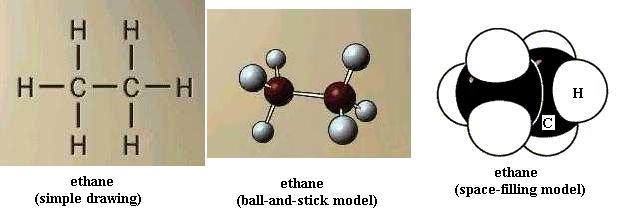
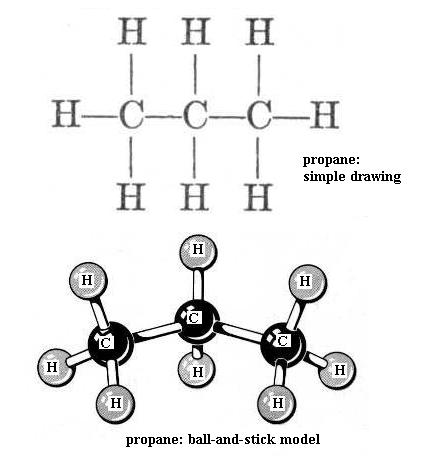
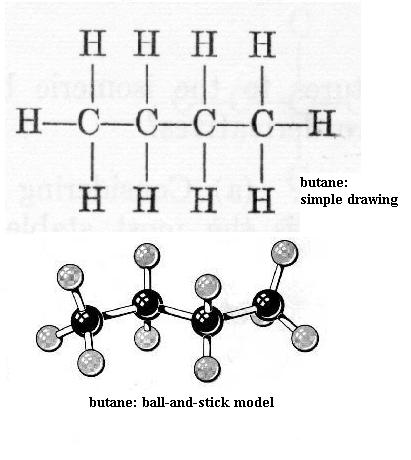
Now build ethane [File menu, then Import Molecule, then moleculs folder, then hydrcarb folder, then ethane.m3d]. All of the bonds are single bonds. Here one of the H atoms of methane has been replaced by a methyl functional group, -CH3. With your left hand hold one C nucleus firmly and rotate the other C nucleus around the axis of the bond connecting the two. This is free bond rotation; the C-C bond is not broken. All of these structural variations of ethane exist. Look at propane [File menu, then Import Molecule, then moleculs folder, then hydrcarb folder, then propane.m3d] and butane [File menu, then Import Molecule, then moleculs folder, then hydrcarb folder, then butane.m3d]. The simple drawing of each shows 90 degree C-H bond angles and shows the C-C "backbone" (chain) as straight (C-C-C and C-C-C-C); that view is incorrect. Build propane and then butane to see that the C chain zigzags; the bond angles are actually about 109 degrees, not 90 degrees. Be sure you understand what is responsible for this effect. Carefully perform free bond rotation around each C-C bond to see the many shapes possible. {You will learn in chemistry courses that due to energy factors only one or a few of the possible shapes of a molecule are favored.} Suppose that the butane backbone actually was straight; would free bond rotation produce as much structural variety then?
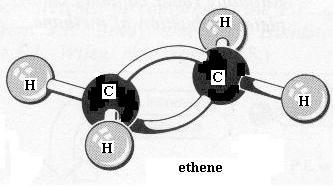
Go back to the ethane molecule and replace the C-C single bond with a C=C double bond. This is ethene. Note the spelling of ethene versus ethane. In order to form the second bond between the two carbon atoms you had to remove one H atom from each carbon. Is there still free bond rotation between the C atoms? between the C and H atoms? To better see what is involved here, dismantle the ethene and construct the two forms of 2-butene: the "cis" isomer [File menu, then Import Molecule, then moleculs folder, then hydrcarb folder, then 2butcis.m3d] and the "trans" isomer [File menu, then Import Molecule, then moleculs folder, then hydrcarb folder, then 2butrans.m3d], as they are called.
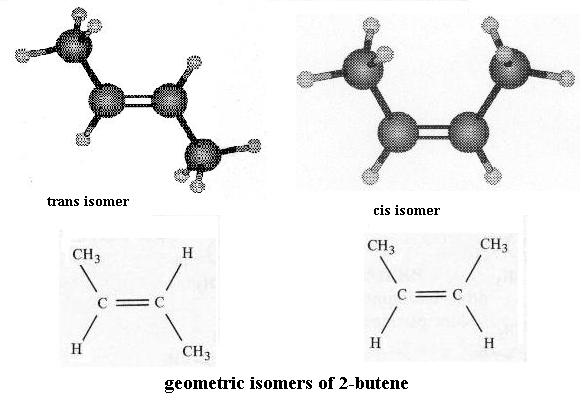
**Isomers are molecules that have the same chemical formula (i.e. same number and type of atoms) but different structures. You'll see more about this important concept later.** Compare these to each other and to butane. First perform free bond rotation with butane and either one of the butene molecules. Can both molecules assume an equally large number of possible shapes? Second, comparing the two butene molecules to each other, note that they have the same kinds and proportion of atoms (4 C each and 8 H each). Also the order of attachment of atoms (what's attached to what) is the same; look closely. However, note that you can't superimpose one on the other, point for point. You can't convert one to the other by free bond rotation without breaking the double bond. There's no free bond rotation at a double bond. So, what effect does a double bond have on molecular structure? These butenes are a pair of geometric isomers; you'll see such again.
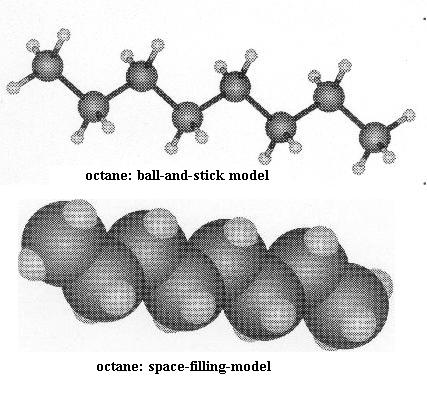
Octane [File menu, then Import Molecule, then moleculs folder, then hydrcarb folder, then octane.m3d] is the 8-C relative of butane. At this point you should be able to imagine what its structure would look like if you constructed it. Now imagine one C=C bond in the octane chain, two C=C bonds in the chain, and so on. Can you write a general rule that says how the number of double bonds in such a chain affects the number of shapes that are possible for a molecule?
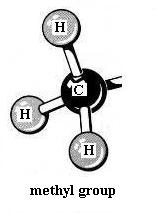
In constructing the models that follow, you will see several functional groups. All of the ones you'll need to know are covered in lecture. You already used the methyl group when you made ethane from methane, then propane, then butane. Review if you didn't notice that.
Carbohydrates: text pp. 45-50
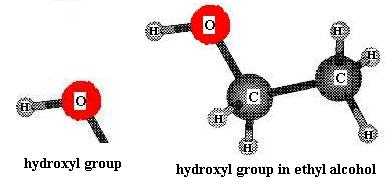
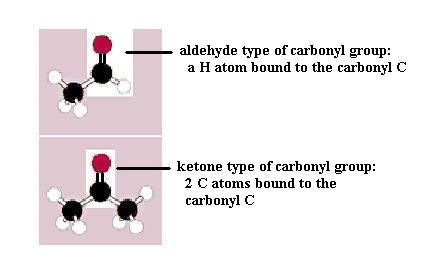
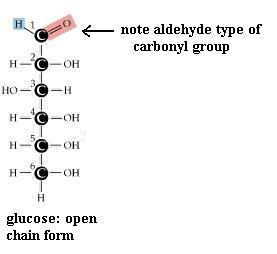
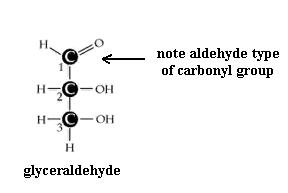
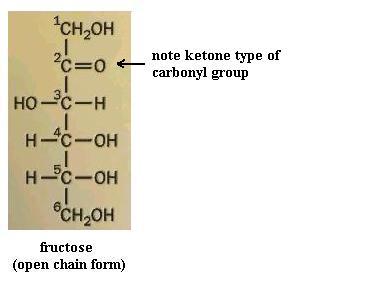
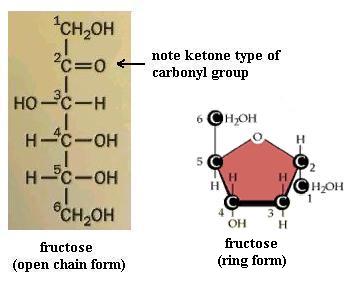
Monosaccharides (the simplest members of the carbohydrate family) have 3 to 7 carbon atoms, 2 or more hydroxyl groups, and a carbonyl group. The hydroxyl functional group is -OH. Like other functional groups, -OH occurs in types of molecules other than carbohydrates in alcohols, such as ethyl alcohol, for example [File menu, then Import Molecule, then moleculs folder, then solvents folder, then ethanol.m3d]. The carbonyl functional group is C=O. If the C atom of the C=O has a H atom attached, then the C=O is the aldehyde type, abbreviated CHO. If the C atom of the C=O has 2 more C atoms attached (no H), then C=O is the ketone type. Therefore, some monosaccharides are also called aldehyde molecules and some are called ketone molecules. For example, glucose and glyceraldehyde are aldehydes; fructose is a ketone.
In Nature the most common monosaccharides are those that have 5 or 6 carbons atoms. Monosaccharides, which are often categorized as "simple" carbohydrates, are also named according to C number: triose (3C), tetrose (4C), pentose (5C), hexose (6C), heptose (7C). Since glucose is both a hexose (has 6 C atoms) and an aldehyde (has the -CHO type of carbonyl functional group), it is also called an aldohexose. Similarly, fructose is a ketohexose; i.e. it has 6 C atoms and has a ketone type of carbonyl group. Both glucose and fructose have the molecular formula C6H12O6 but different structures; therefore, they provide a second example of a pair of isomers. Note also that the "ose" ending of chemical names usually signifies a carbohydrate.
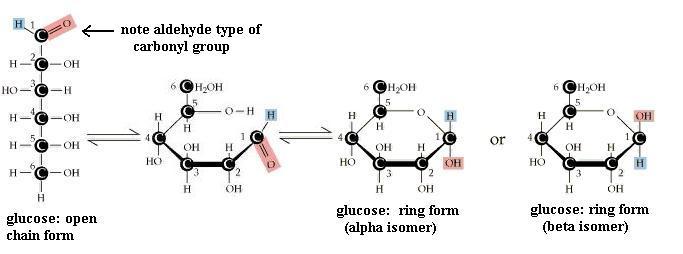
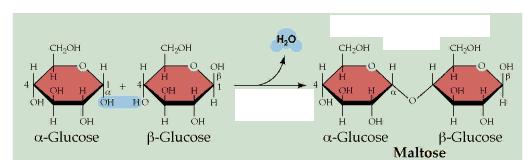
Pentoses and hexoses may exist in either an open chain form or a closed ring form. As shown for glucose, free bond rotation allows the glucose chain to roll around so that C#1 and C#5 come close together and react with each other, to form a closed ring. This ring form is more stable and, therefore, more common. Trioses and tetroses exist only as the open chain form since trying to close a ring would strain the bonds too much.
Build a model of the open chain form of glucose. Is the carbon chain actually straight? Does the molecule have a single fixed shape?
Now convert this open chain form to the ring form
of glucose as follows:
(1) Remove the =O from C#1 and replace the flexible bond pieces
on the O atom with green cylinder bonds. (2) Remove the H atom from
the OH group on C#5, leaving the green cylinder bond on the O atom attached
to C#5. (3) Attach that free H atom to one of the free O atom's
bonds to make an OH group. (4) Attach that new OH to C#1.
(5)
Carefully
perform free bond rotations to bring C#1 close to C#5, which has an O atom
with a free green cylinder bond on it. (6) Then attach C#1
to the open bond on the O atom of C#5.
Your molecule should have the -OH groups arranged as in one or the other of ring structures shown. You may have the alpha form or the beta form. Alpha glucose [File menu, then Import Molecule, then moleculs folder, then carbohyd folder, then glucosa.m3d] has C#1 -OH pointed "down," whereas beta glucose [File menu, then Import Molecule, then moleculs folder, then carbohyd folder, then glucosb.m3d] has C#1 -OH pointing "up." Closing the open chain into a ring converts the C=O group into an -OH on C#1. These two ring forms are freely interconvertible in solution, because the ring will spontaneously open and reclose, again and again. If you have trouble converting the chain to the ring (it's not as easy as it might seem) to get the correct ring structure, then start with the ring and open it to recreate the chain, to satisfy yourself that one does become the other. NOTE that in the open chain form, there is no distinction of alpha versus beta forms of glucose, since there is no -OH group on C#1 in the open chain form. Fructose, a ketone type of monosaccharide, also exists in a ring from [File menu, then Import Molecule, then moleculs folder, then carbohyd folder, then frctfrns.m3d]
How does ring closure affect structural variability? That is, can the ring form of glucose have as many different structural shapes as the chain form of glucose? Is this 6-member glucose ring actually flat (planar)? Why/why not? Where is the carbonyl group in the glucose ring? Can you convert the ring to the chain without breaking bonds? How many carboxyl groups are in this molecule? How many dissociable groups? Could you convert an alpha glucose molecule to a beta glucose molecule without breaking any bonds?
Now construct a second glucose ring beta glucose this time; and then form a maltose molecule [File menu, then Import Molecule, then moleculs folder, then carbohyd folder, then maltose.m3d] by dehydration synthesis between C#1 of the alpha glucose and C#4 of the beta glucose. Maltose is a disaccharide. What is the other product of this reaction? Do the two glucose rings lie in the same plane? What are the products of hydrolysis of maltose? of sucrose (table sugar)? of lactose (malt sugar)? Disaccharides are also categorized as "simple" carbohydrates.
On paper draw generalized structures of a ketopentose and an aldotetrose.
The molecular weights of C, H, and O are 12, 1, and 16 daltons, respectively. Therefore, both glucose and fructose have molecular weights of 180 daltons. What is the molecular weight of sucrose? Do the open chain and closed ring forms of glucose have the same molecular weight?
Just as you can make a disaccharide from two monosaccharides, by dehydration synthesis, polysaccharides are made by bonding together many monosaccharides by dehydration synthesis. And the issue of -OH groups pointing up or down on the rings leads to remarkable differences in the properties of the polysaccharides. For example, both starch and cellulose are made from many hundreds of glucose molecules, but it's alpha glucose in starch and beta glucose in cellulose. One interesting result of that "tiny" difference is that starch is digestible but cellulose is not. For another, starch is water soluble, but cellulose is not. Polysaccharides are also called "complex" carbohydrates. Those that are not digestible are often called dietary "fiber".
Since -OH and -C=O functional groups can form hydrogen bonds with water (especially -OH), carbohydrates as a group are quite water soluble. Cellulose and a few others are notable exceptions.
Unlike the carbohydrate family, which has a pretty well defined set of structural features (see class notes again) that biologists agree on, the lipid group is less well defined. All lipids are hydrophobic molecules, but beyond that there is less agreement on what should be included in the lipid group. Fatty acids, glycerides, phospholipids, and steroids are the ones we need to know about.
A. Fatty acids
Molecules that contain the carboxyl functional group, as illustrated in acetic acid, [File menu, then Import Molecule, then moleculs folder, then acidbase folder, then aceticac.m3d] are known as carboxylic acids. The carboxyl group gives them their acidic character. Those that have a relatively long carbon-carbon chain are called fatty acids because they occur commonly within fat molecules (more about that below). Acetic acid gives vinegar its familiar odor.
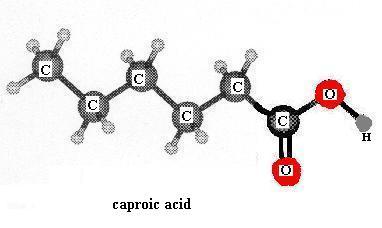
Build the model of caproic acid: CH3CH2CH2CH2CH2COOH. This is a small (short chain) member of the fatty acid family. Aside from the hydrophilic carboxyl group at one end, the rest of a fatty acid molecule (the bulk of it) is made of methyl groups linked together (-CH2-) and those are hydrophobic. As discussed in class, members of this family having more than about five carbons are water-insoluble. Is more than one shape possible for the caproic acid molecule? If you built a model of stearic acid [File menu, then Import Molecule, then moleculs folder, then biomolec folder, then stearic.m3d] by extending the carbon chain of caproic acid to18 carbons, would it have more, less, or the same number of possible shapes as the number for caproic acid? Can you write a general rule that relates the length of a fatty acid chain (carbon skeleton, backbone) to the number of shapes possible.
The carboxyl group of these molecules can undergo reversible dissociation:
-COOH ![]() -COO-
+
H+. For acetic acid as an example, that's represented as: CH3COOH
-COO-
+
H+. For acetic acid as an example, that's represented as: CH3COOH ![]() CH3COO- + H+. Therefore, depending on
the pH (i.e. the H+ ion concentration) of the surrounding solution,
a free fatty acid's carboxyl group is uncharged (pH < 4 approx.) or
bears a negative charge (pH > 4 approx.).
CH3COO- + H+. Therefore, depending on
the pH (i.e. the H+ ion concentration) of the surrounding solution,
a free fatty acid's carboxyl group is uncharged (pH < 4 approx.) or
bears a negative charge (pH > 4 approx.).
Generally, are carbohydrates more or less water soluble than fatty
acids? Why?
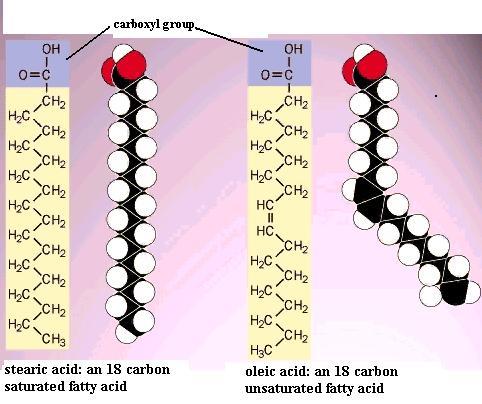
Build a second model of caproic acid and put a double bond between C3 and C4. This molecule is "unsaturated", by definition, because of this C=C double bond. The first one you made is "saturated", by definition, because there are no C=C double bonds in the carbon chain. Note that "saturation" here has nothing to do with water. The presence of the double bond means that there are two geometric isomer forms of this unsaturated fatty acid molecule: the cis isomer and the trans isomer. Recall the two different arrangements of the atoms around the C=C double bond in the 2-butenes that you constructed. In the cis isomer the double bond interrupts the regularity of the zigzag in the chain; i.e. it causes a "bend" in the chain. Compare oleic acid [File menu, then Import Molecule, then moleculs folder, then biomolec folder, then oleic.m3d] with stearic acid. In most naturally occurring unsaturated fatty acids that C=C double bond has the cis structure.
This effect of double bonds is important in fat and phospholipid molecules. For example, stearic acid has a melting point of 70 C whereas oleic acid melts at 16 C. This effect on melting point applies to all of the long chain fatty acids and to the fats made from those fatty acids; more double bonds lower the melting point even more. Therefore, saturated fats tend to be solids at room temperature (as in lard, butter, shortening), but unsaturated fats tend to be liquid at room temperature (as in oils derived from various plants). **In phospholipid molecules that bend in the fatty acid chains keeps the molecules from packing together side-to-side as tightly as they might, which profoundly affects the properties of cellular membranes (more about that in lecture).**
Is there free rotation at a double bond in a fatty acid chain? Polyunsaturated means that the fatty acid chain (skeleton, backbone) contains two or more C=C double bonds. The more double bonds there are in the chain, the more bends there are. Would a 16-carbon polyunsaturated fatty acid have more or less possible shapes that a 16-carbon saturated fatty acid? Can you convert the cis isomer to the trans without breaking bonds?
B. Fats (= triglycerides = triacylglycerols)
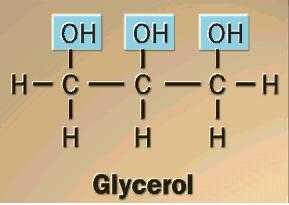
Construct a model of glycerol. Is it a carbohydrate? (Hint: look at glyceraldehyde again. How do we define "carbohydrate?") Would you expect glycerol to be hydrophilic? Be able to explain.
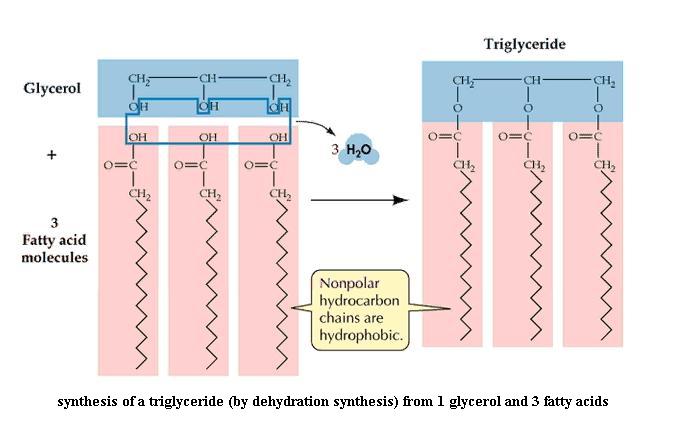
Construct a third model of caproic acid. You need three molecules of caproic acid and one glycerol to proceed. These three short chain fatty acids will represent any three fatty acids that might be found in fat molecules. Attach one of the fatty acid molecules, then a second, then the third, to the glycerol molecule by performing dehydration synthesis. Note that water is a product of the reaction. A monoglyceride (= monoacylglycerol) molecule is one fatty acid chain attached to glycerol. A diglyceride (= diacylglycerol) molecule is two fatty acid chains attached to glycerol. And a triglyceride (= triacylglycerol) molecule is three fatty acid chains attached to glycerol. "Fat" molecule is a synonym for triglyceride. Are fats water soluble?
Note that fats are not charged. All three carboxyl groups are bonded to the glycerol; they cannot release or accept H ions. The triglyceride illustration suggests that all three fatty acid chains lie side by side on one side of the glycerol backbone. With the model in your hands, is that necessarily so?
It is important to understand that there are many different individual types of fats possible, depending on: (a) the lengths of the fatty acids, which may differ at the three glycerol positions, (b) whether the fatty acids are unsaturated (mono-, poly-) or saturated. Combinations are possible.
Write the dehydration synthesis that you did to make this fat molecule, in the form of a chemical reaction: reactants at the left, products at the right, with an arrow between pointing left to right. Again, the reverse of dehydration synthesis is called hydrolysis (verb: hydrolyze). This reaction breaks the previously made bond between glycerol and a fatty acid by adding back the components of water (H and OH). If you hydrolyze a fat molecule, as happens to dietary fats in your small intestine, what products do you get, and in what numbers? {To jump back for a moment, what is produced when a polysaccharide is hydrolyzed completely? and when a disaccharide is hydrolyzed?}
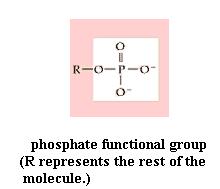
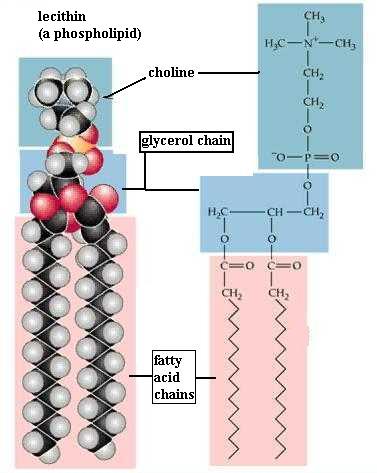
Phospholipids
Since your kit does not contain phosphorous atoms, you can't make a phospholipid. However, your experience in studying the fat molecule gives some insight into the structure of a phospholipid. The name reflects the fact that they contain the phosphate functional group (-PO4). The typical traits are illustrated by lecithin [File menu, then Import Molecule, then moleculs folder, then biomolec folder, then lecithin.m3d]. As in a diglyceride, fatty acid molecules are attached (by dehydration synthesis) to the first and second of glycerol's C atoms. However, the third glycerol C atom bears a phosphate functional group (negatively charged and hydrophilic). Attached to the phosphate is another small hydrophilic molecule, such as choline in the lecithin molecule. The two fatty acids typically are unsaturated (cis C=C bonds), which kinks those chains, as you saw in oleic acid.
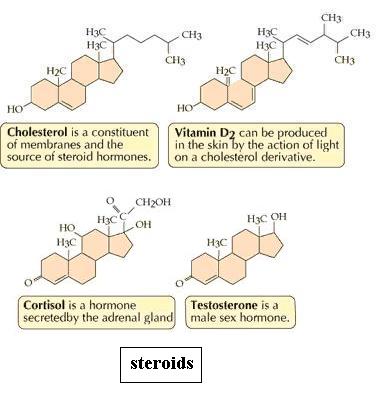
Steroids
Dismantle the fat molecule and then build the cholesterol molecule [File menu, then Import Molecule, then moleculs folder, then biomolec folder, then cholstrl.m3d]. You see four fused rings, collectively called the "nucleus" of the molecule. The part attached at the top right is called the "side chain." To save some time, you may leave off the many H atoms. Is there free bond rotation within the nucleus? Viewed from the edge, the rings of the nucleus should lie almost in the same imaginary plane, suggesting an overall "flatness." What effect does ring closure have on structural variation? (That question was asked about monosaccharides too.) Would you expect cholesterol to be hydrophilic? Why? Would cortisol [File menu, then Import Molecule, then moleculs folder, then biomolec folder, then cortisol.m3d] be more or less soluble than cholesterol? Why? Cholesterol contributes to "plaque" formation in arteries, a factor in atherosclerosis, which can cause stroke or heart attack. Given that blood is mostly water, do you see any connection between understanding properties of molecules and real situations?
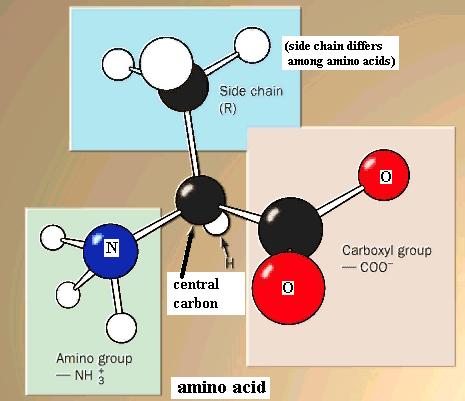
Amino acids and peptides text pp. 38-45
Amino acids, as a family, are defined by the presence of both an amino functional group (-NH2 or -NH3+) and a carboxyl functional group attached to the same carbon atom, which we will call the central carbon atom. Also attached to the central carbon atom is a H atom and a "side chain." Your text shows structures of the amino acids commonly found in living organisms.
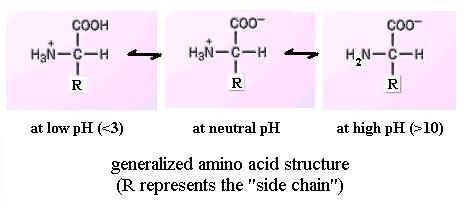
Like the carboxyl group, the amino group is also reversibly dissociable:
NH2 + H+![]() NH3+ However, it gains or loses a H ion at
high pH values, in the range pH = 9 to 10 approximately, depending on the
particular amino acid. Thus, the amino group itself may be electrically
neutral or positively charged, depending on solution pH. And an amino
acid molecule's net charge may be positive, zero, or negative.
Net charge is the sum of all charges on the functional groups within a
molecule. Since most biological solutions are near pH 7 (neutrality),
most amino acids would have both of these functional groups charged.
Further, reference to your textbook shows that a few amino acids have an
extra amino or carboxyl group in the side chain; pH affects the charge
of those too.
NH3+ However, it gains or loses a H ion at
high pH values, in the range pH = 9 to 10 approximately, depending on the
particular amino acid. Thus, the amino group itself may be electrically
neutral or positively charged, depending on solution pH. And an amino
acid molecule's net charge may be positive, zero, or negative.
Net charge is the sum of all charges on the functional groups within a
molecule. Since most biological solutions are near pH 7 (neutrality),
most amino acids would have both of these functional groups charged.
Further, reference to your textbook shows that a few amino acids have an
extra amino or carboxyl group in the side chain; pH affects the charge
of those too.
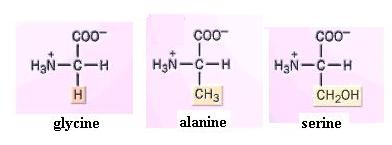
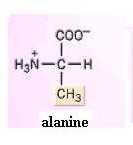
Build models of glycine, alanine, and serine.
[File menu, then Import Molecule, then moleculs
folder, then aminoac folder, then glycine.m3d]
[File menu, then Import Molecule, then moleculs
folder, then aminoac folder, then alanine.m3d]
[File menu, then Import Molecule, then moleculs
folder, then aminoac folder, then serine.m3d]
What is the side chain in each? Since the amino group can readily form H-bonds with water, amino acids, as a group, are hydrophilic. Their side chains strongly influence this. You should now be able to infer the relative solubilities of most of the amino acids shown in the textbook. For instance, would you expect serine or alanine to be the more water-soluble? Why?
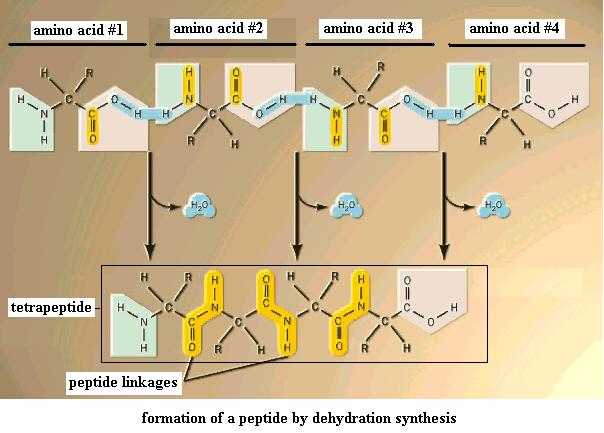
Now use these amino acids to perform dehydration synthesis between the amino group of one molecule and the carboxyl group of another. Two amino acids so bonded together form a dipeptide. Two alanine molecules bonded this way can be seen at [File menu, then Import Molecule, then moleculs folder, then biomolec folder, then alaala.m3d]. Add a third amino acid the same way to get a tripeptide, and so on. This is the third case of dehydration synthesis you've seen. It's important to recognize this as the same type of reaction. The covalent bond that you just made to hold the two amino acids together is given the special name, peptide bond, or peptide linkage. (Note: there's no such thing as a "monopeptide".) Get the idea? Several amino acids so bonded would produce an oligopeptide, and many so bonded together would produce a polypeptide. A polypeptide that has been folded into its final 3-dimensional form is generally referred to as a protein.
The amino acid sequence is very important in determining the properties and behavior of peptides and proteins in organisms. The tripeptide serine-alanine-glycine is not identical to the glycine-serine-alanine molecule. How many different tripeptides could you make from these three amino acids if you were allowed to use the same one two or three times? That is, how many combinations (or sequences) are possible? Since proteins typically have 100+ amino acid units in them, but there are only about 20 different types of amino acids in proteins, obviously some or all of the 20 types must be used repeatedly in making a protein. In even a small polypeptide the number of sequences possible is enormous. What are the products of hydrolysis of a pentapeptide?
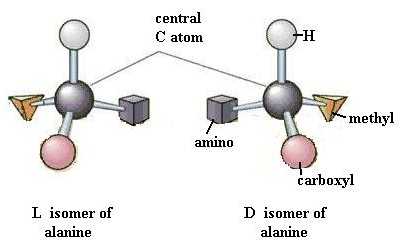
Dismantle the tripeptide and build two identical models of alanine. Your two identical alanine molecules are superimposable on each other, point for point. Now rearrange the functional groups of one molecule so that the two molecules are mirror images of each other. These two molecules are very similar, but different in a very important way, just as your two hands are. Look at them. Are they (hands or molecules) superimposable on each other, point for point? One of these alanine forms is the D isomer and the other is the L isomer. This property of "handedness", or asymmetry, is found in many biologically important organic molecules and is extremely important in the functioning of molecules. As a rule, living systems have L forms amino acids but D forms of monosaccharides.
DISMANTLE THE MODEL PIECES COMPLETELY AND PUT THEM IN THE PLASTIC BAG. RETURN TO THE TA.
STEREO PAIRS
A stereo pair is a side-by-side pair of images of the same object as seen from slightly different angles. Your eyes provide stereo vision; they see a given object from two slightly different angles. Your brain combines those two images to give a single three-dimensional (3-D) image. For observing these stereo images in lab with the stereo viewers, printed copies of the images will be provided there.
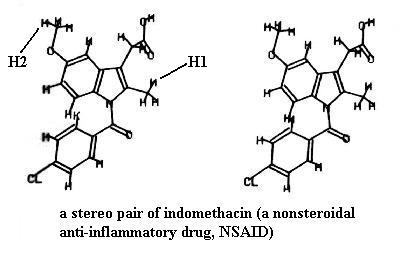
Look at the two drawings of indomethacin (a pain reliever). You could have built this molecule. The drawings are very similar but not identical; they show the same molecule drawn from two slightly different angles. Certainly the molecule looks flat in both drawings, but if you can mentally fuse the two drawings, you will see a single 3-D view of the molecule. Your TA will explain to you how to use the stereo "glasses" to see this. It is quite a remarkable effect if you've never seen such. You will know when you really have the 3-D view. For example, the methyl group in the upper left corner of the molecule (marked H2) is obviously farther away than the methyl group protruding from the right side (marked H1). You'll note that the rings are also tilted at very different angles in the 3-D view.
Another way to get the 3-D effect, which can be done on a computer screen too, is to hold an index card (or something similar) vertically between the two images like a wall. Then as you stare down at the edge of the card, the images will move and eventually fuse into one 3-D image.
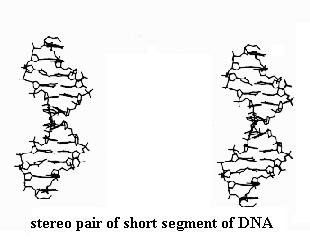
Observe also the stereo pair of a very short segment of DNA, which is a double helical molecule. It resembles a twisted ladder. Its two "strands" are precisely wrapped around each other. Your stereo viewer nicely shows this feature and the way certain parts of the molecule form the rungs of the twisted ladder. We'll study these features later in the course.
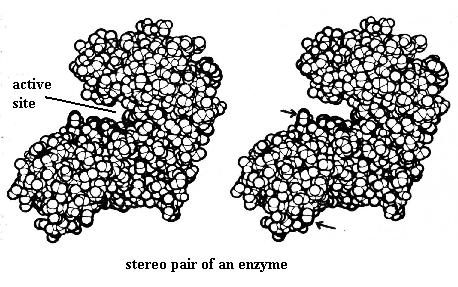
Finally, observe the stereo pair of the enzyme molecule, showing the notch (active site) where the enzyme executes its chemical reaction. When you have established the 3-D image you will see that the "bump" marked by the upper arrow is farther away than that marked by the lower arrow.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}